

Barret
Wednesday, July 13, 2022 | 8 minutes
A Brief Introduction to Azure Data Factory
Over the last year or so I’ve had a chance to delve deeply into one of Microsoft’s newer Azure offerings: Azure Data Factory (ADF). This post is a summarized version of a talk I’ve given at a few conferences and meetups in recent months.
A huge part of what we deal with in tech is data. It’s everywhere, and it’s only getting bigger. It used to be that if we needed to move data between different systems or data sources, we would have to spend hours, days, or even weeks writing some custom integration that would take the data from one system and convert it to be imported into a different system.
That’s where ETL software comes into play. ETL stands for Extract, Transform, Load. It, and its alternative ELT (Extract, Load, Transform), refers to a category of software products designed to move massive amounts of data between different data sources (with or without some form of data transformation).
The biggest difference between ETL and ELT products are that with ETL, the data is manipulated before being delivered to the destination. With ELT products, the data is manipulated after being delivered to the destination data source.
You might move data from a spreadsheet to SQL Server, SalesForce to an ERP, a web API to your ticketing system, or your HR system to a data warehouse. The possibilities are only limited by the data sources that your ETL product supports.
ETL products have been around for decades and there are a vast number of ETL/ELT products on the market. Some of them are cloud-based, some are server-based, some are desktop software products, and some are plug-ins available for other data software products.

A small sample of available ETL/ELT products
Azure Data Factory
Introduced a few years ago on their Azure cloud platform, ADF is a primarily GUI based, serverless, fully managed ETL tool that excels at moving data between a large variety of data sources–more than 90 different data sources at last count.
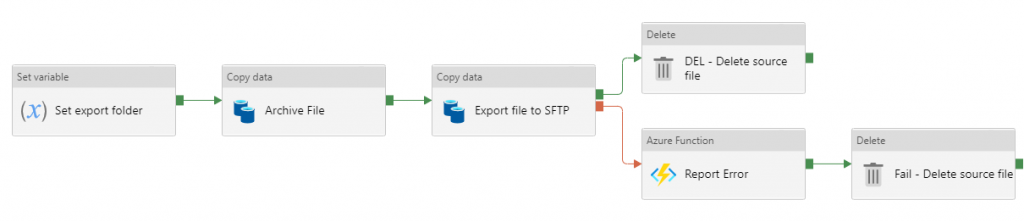
The user interface is designed around a flowchart-style workflow, allowing you to tie together a series of activities, which work together to get your data from the source to the destination. Along the way you can use other activities to do any data manipulation you might need to do in transit such as converting data formats, redacting personally identifiable information, merging data together, or adding autogenerated and calculated fields of data.
Azure Data Factory UI example
Pipelines
A workflow in ADF is known as a pipeline. The pipeline represents the complete set of actions that a workflow will undertake. A pipeline may contain up to 40 actions in total, but one of those actions allows a pipeline to call another pipeline, so theoretically there isn’t an effective limit to the number of actions a pipeline can carry out.
Triggers
A pipeline can be triggered in three ways. The first method is to run it on a schedule. While not completely as flexible as your typical cron job scheduling, scheduled triggers for ADF can be set up in almost any way you might need.
The second trigger method for a pipeline is a file event in Azure blob storage. This can either be a file created event, or a file deleted event. When these events occur, the trigger can pass in various pieces of information about the file that triggered the event. This method is perfect for triggering a pipeline to process a file that gets dropped into blob storage.
The third type of trigger is an external trigger. A pipeline can be triggered from an external source, such as a web server call. One typical approach to this is to set up an Azure function that triggers an ADF pipeline based on some programming result, or as the result of some action in an ASP.NET web API function.
Activities
Each step in the pipeline is known as an activity. ADF has a wide variety of activities that it can carry out. The most common one is the “Copy data” activity, which moves data from one place to another and is capable of doing some simple data manipulation along the way. Examples of this might include copying data from a CSV file to a SQL database table, or calling a web API to pull data into SalesForce
For more complex data conversions there is a data flow activity, which allows you to do more complex data manipulation such as merging multiple data sources together or generating multiple output files.
Other activities include things like conditionals, iterators, calling web endpoints or Azure functions, interacting with data bricks, power query calls, u-SQL calls against data lake sources, calling machine learning processes, and so forth.
Datasets & Linked Services
A particular set of data in ADF is called a dataset, funnily enough. A dataset represents a block of data from a particular data source. A dataset might be the data in a SQL table, the rows from a CSV file, the results of an Azure function call, and so forth.
The connections to the various data sources are known as linked services. A linked service might be a SQL Server, a website, a CSV file, a Salesforce instance, and so forth. The credentials for these various connections can either be stored in the ADF configuration for the linked service or stored in Azure Key Vault for retrieval and use. It’s important to remember that any created connection will be available to any pipeline in that particular instance of ADF.
So in general, activities manipulate the data in datasets, which comes from, or is saved to, linked services.
Integration Runtimes
The last general concept to keep in mind for ADF is that of integration runtimes. These runtimes are the “server” that runs various pieces of your ADF pipeline. By default, each instance of ADF has one Azure-hosted integration runtime, usually named the AutoResolveIntegrationRuntime. Additional IRs can be created in Azure to help balance the load of your ADF pipelines.
In addition to these Azure hosted IRs, if you wish to create linked services to resources located on your on-prem networks, such as SQL Server or network file servers, you will need to install an IR on a server on your network and connect it to your Azure ADF instance. Any pipeline activities that interact with on-prem resources will run via these on-prem installed runtimes.
Source Control - Git, CI/CD Pipelines & Publishing
ADF has built-in integration with Azure DevOps or other git-based repositories. Branching and merging strategies work the same way that any other git-based source control strategy works, with an important distinction, which I’ll come back to in a moment.
First, though, the source code for an ADF pipeline consists of a block of JSON which looks like the following:
{
"name": "DL_File_Test1",
"properties": {
"activities": [
{
"name": "Copy data1",
"type": "Copy",
"dependsOn": [],
"policy": {
"timeout": "7.00:00:00",
"retry": 0,
"retryIntervalInSeconds": 30,
"secureOutput": false,
"secureInput": false
},
"userProperties": [],
"typeProperties": {
"source": {
"type": "AzureSqlSource",
"queryTimeout": "02:00:00",
"partitionOption": "None"
},
"sink": {
"type": "DelimitedTextSink",
"storeSettings": {
"type": "AzureBlobFSWriteSettings"
},
"formatSettings": {
"type": "DelimitedTextWriteSettings",
"quoteAllText": true,
"fileExtension": ".csv"
}
},
"enableStaging": false,
"translator": {
"type": "TabularTranslator",
"typeConversion": true,
"typeConversionSettings": {
"allowDataTruncation": true,
"treatBooleanAsNumber": false
}
}
},
"inputs": [
{
"referenceName": "Workers",
"type": "DatasetReference"
}
],
"outputs": [
{
"referenceName": "DL_WorkersTest1",
"type": "DatasetReference"
}
]
}
],
"annotations": []
}
}
When you look at pipelines stored in git, you will see each pipeline, dataset, dataflow, trigger, and template represented as a separate JSON file in the git repo.
As for the distinctions. First, each ADF environment you connect to a git repo will have a primary branch. Your strategy for development would be to create a branch off of that main branch, do your development, then merge it back into the primary branch. Makes sense, right? However, when you merge back into the primary branch, this does NOT actually make your update active on the ADF server.
This is something a lot of people just learning ADF miss and they waste hours wondering why their merged code isn’t working right. First, before your code become active on the ADF environment, you have to publish it. On publish, the system will first validate your code and look for any errors. Any errors will prevent your code from being published and taking effect until you fix the error.
Generally speaking the best practice for ADF is to use different repos for each ADF environment and then make use of Azure DevOps CI/CD pipelines to migrate code from one environment to another.
Getting Started & Pricing
Getting started with Azure Data Factory is simple. All you need is an Azure account and you can create an ADF instance in just a few minutes. One thing to keep in mind, however, is that ADF does not have a free tier. It’s straight usage pricing. ADF is targeted at massive datasets on an enterprise level and not really aimed at personal or small business users.
While it’s not especially expensive to do a little bit of learning, it’s also not free. Take this example from the ADF docs. Based on current pricing, copying a small file from AWS S3 to Azure Blob costs roughly $0.17.
You can get started with the documentation here.
